
Tudo o que você precisa saber sobre Classificação Multirrótulo - Parte 3 (Final)

")
Combinação de Classificadores Multirrótulo
Lembram que eu comentei que a gente tem vários algoritmos para lidar com o problema multirrótulo? E então eu comentei sobre a abordagem local e global, lembram?
Pois bem, para melhorar ainda mais o nível de predições dos rótulos, podemos fazer uma combinação de classificadores ao invés de usar um único classificador. Por exemplo, o BR que eu expliquei lá no primeiro artigo, pode ser combinado de forma que o que é aprendido por um classificador BR pode ser usado por outro classificador BR.
No segundo artigo, eu trouxe um exemplo de dataset com 5 rótulos e comentei que no caso do BR precisamos de 5 classificadores BR, um para cada rótulo. Pois bem, usando o esquema de combinação, podemos pegar o resultado de cada um desses 5 classificadores e combiná-los ao final. Que tal uma imagem para visualizar melhor?
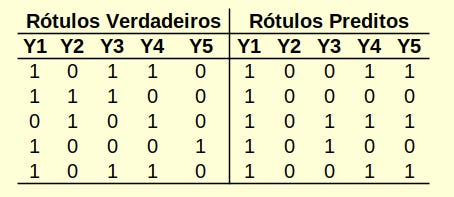
A Figura 1 ilustra os rótulos originais do dataset (rótulos verdadeiros), assim como as predições feitas pelos classificadores BR (rótulos preditos). Claro que aqui eu inventei tudo tá pessoal, e foi de um jeito bem descarado que é para facilitar a visualização de todas as situações. Em Y1 vemos que ele acertou 4 das 5 predições, isto é, onde era para prever 1 ele preveu 1 e onde era para prever 0 ele preveu 0.
A gente vai olhar para os outros rótulos agora e verificar o mesmo: onde o rótulo predito é igual ao rótulo original? Com isso a gente tem uma ideia já do quanto que os classificadores acertaram individualmente, mas para predição final, a gente precisa usar medidas específicas de multirrótulo, as quais introduzirei em outra seção neste artigo.
O importante aqui é vocês saberem que existem os rótulos verdadeiros e existem os rótulos preditos pelos classificadores. Portanto, em uma combinação de classificadores, cada classificador base é executado separadamente, e então as predições de cada um são agregadas para realizar uma predição final e é assim que conseguimos aumentar o poder preditivo.
Outras questões podem ser tratadas quando se trabalha com a combinação de classificadores, como o desbalanceamento de classes e as correlações entre os rótulos, por exemplo.
Propriedades dos Dados Multirrótulo
Outro tema importante sobre classificação multirrótulo são as propriedades dos dados e não estou falando aqui sobre atributos de entrada e saída. Conjuntos de dados multirrótulo possuem diversas propriedades que podem ser mensuradas e as quais caracterizam este tipo de dado.
É possível obter desde informações simples como número total de rótulos, número total de instâncias, número total de conjuntos de rótulos distintos, até informações mais complexas como o nível desbalanceamento do conjunto, esparsidade do espaço de rótulos e de instâncias, entre outros.
Essas informações auxiliam na resolução do problema multirrótulo, podendo ajudar na escolha das técnicas a serem utilizadas e também na escolha do algoritmo mais adequado para o problema em questão.
Por exemplo, a cardinalidade calcula a média de rótulos por instância. A partir desse valor podemos saber quantos rótulos existem para cada instância, na média hein!
Quanto maior o valor da cardinalidade, maior é o número de rótulos relevantes por instância, e quanto mais baixo esse valor, menor é esse número. Um dataset em que a cardinalidade é extremamente baixa indica que a grande parte das instâncias pertence a um único rótulo e talvez um classificador como o BR consiga ter um melhor desempenho do que um classificador multirrótulo.
Existem outras propriedades como densidade, proporção de combinações de rótulos, porcentagem de instâncias rotuladas com um único rótulo, frequência de rótulos, frequência de conjuntos de rótulos, número de conjuntos de rótulos distintos, nível de desbalanceamento de classes, nível de concorrência entre os rótulos minoritários e majoritários, etc. Não falarei de cada uma delas aqui pois não há espaço, mas tratei um artigo específico detalhando-as.
Medidas de Avaliação
Finalizando essa série de artigos, falo agora de como avaliar o resultado de um classificador multirrótulo. Como mencionei anteriormente, uma das coisas que conseguimos notar é o quanto o classificador acertou de predições olhando para as predições verdadeiras. Em tarefas de classificação podemos fazer isso.
É justamente por isso que precisamos dividir o nosso conjunto de dados em treino, teste e algumas vezes em validação também, depende do trabalho. Com o treino, o classificador aprender e, com o teste, conseguimos verificar se o classificador acertou as predições daquele conjunto de teste. Lembrando que as classes não são passadas para o classificador no momento de teste! Ele tem que tentar adivinhar quais são as classes a partir do que aprendeu.
Existem muitas medidas de avaliação e vou escrever um artigo apenas sobre elas, então aqui vou introduzir o assunto. Para poder calcular o nível de acerto das predições, nós precisamos dos valores preditos para todos os rótulos, que normalmente estão em 0 e 1, assim como na Figura 1. Conseguimos obter muitas informações a partir desta tabela, vamos dar uma olhadinha.
A Figura 2 mostra os valores dos rótulos verdadeiros e dos rótulos preditos, assim como a soma das instâncias positivas e negativas. A terceira parte da Figura onde está Ŷ == Y nos diz se o rótulo predito é igual ao rótulo verdadeiro: se sim vale 0, se não vale 1. Com isso a gente tem o número de erros: Ŷ1 errou uma predição, Ŷ2 duas, Ŷ3 errou todas, Ŷ4 não errou nenhuma e, Ŷ5 errou quatro. Aqui já dá para ter uma noção do quão boa ou ruim foi a predição.
A situação em que todas as predições foram erradas não é boa (Ŷ3), mas uma situação em que todas as predições estão certas (Ŷ4) também pode ser preocupante pois pode indicar super aprendizado. É aí que as diversas medidas nos auxiliam a analisar com mais cuidado os resultados.
Finalizando, a partir dessa tabela a gente consegue calcular várias medidas de erros e acertos de predição, entre elas acurácia, revocação, predição, hamming loss, macro-predição, macro-revocação, macro-f1, clp, mlp, etc. A explicação detalhada ficará para um próximo artigo.
Conclusão
Com isso encerro essa série de artigos introdutórios. A partir de agora começarei a aprofundar os assuntos. Espero que vocês me acompanhem nessa jornada! Até a pŕoxima.
Este artigo foi escrito por Elaine Cecília Gatto - Cissa e publicado originalmente em Prensa.li.